
1. 问题
知乎网友 Shinnku 问:
我(提问者)最近在写C++程序时发现编译器并不是单纯的靠类型检查来实现const的类型安全的。我之前认为只有下面一种方式:
#include <iostream>
#include <stdio.h>
const char name[] = "Hello World";
int main() {
(char*)name[2] = '3';
//编译器直接报错,const char[13]不能转成(char*)
std::cout << name << std::endl;
return 0;
}
但是请看下面的代码:
#include <iostream>
#include <stdio.h>
const char name[] = "Hello World"; //const char[13]
template<typename _Ty> void f(_Ty param) {
std::cout << param << std::endl;
printf("%p\n", ¶m[2]);
param[2] = '3';
};
int main() {
printf("%p\n", &name[2]);
f((char*)name);
std::cout << name << std::endl;
return 0;
}
成功编译,但却仍然无法在那块区域写入内容,在VC中运行上面代码,有如下图的报错:
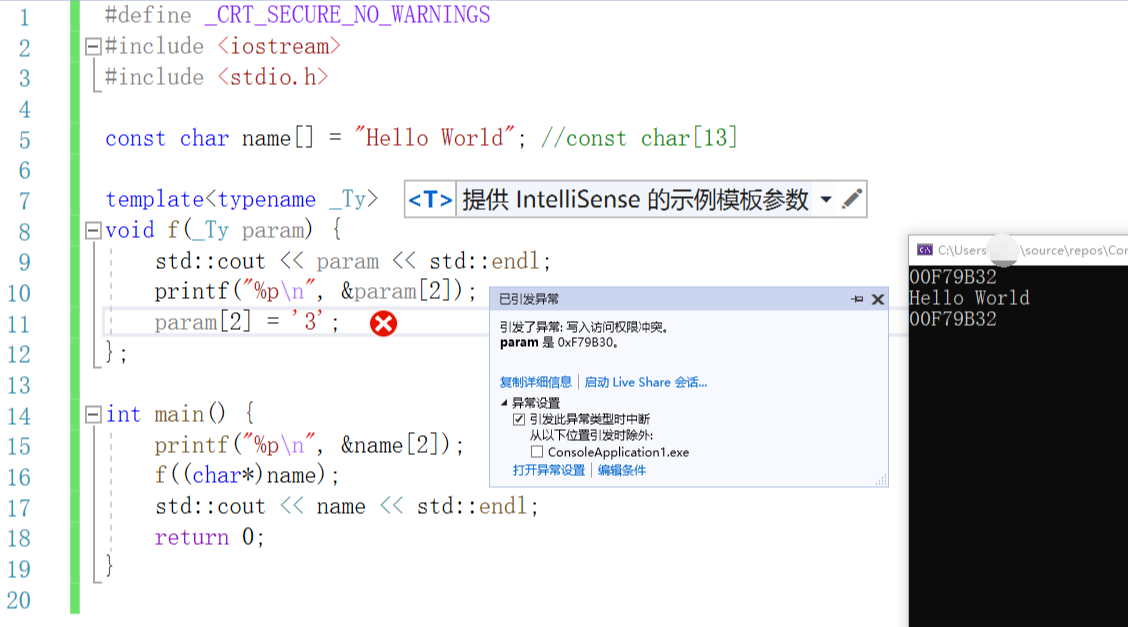
请问是什么原因能让C++保持在运行之后占有那块内存却无法写入的?
编者注:
提问者后面的代码逻辑是:
(1) name 是常量字符串(字符指针),其内容按理不允许被修改;
(2) 但在 main() 中调用f,通过C风格强制转换 (char*)name,将它转成非常量字符指针;
(3) 于是等真执行到 f() 里头,第11行修改 param[2],相当于是要修改 name 的内容(而name在根源上可是常量,于是运行出错,发生如图中的“写入访问权限冲突”;
(4) 提问者想问:程序是不是具备某种机,所以能够及时发现我们的非法企图(试图修改常量),然后及时“甩脸”(中止程序);
(5) 另外,对比第一段测试程序,为什么前者能直接在编译期就报错,而后者却是在运行时才报错?
2 南老师的回答
哈哈哈哈,好多人批你(却不知自己中招你的障眼法),并没说到点子上啊,所以我猜你可能会郁闷。
我可能也会说得比较凶狠或过头,望能理解。
一、你的第一个错:基础不扎实
//你写的代码:
(char*)name[2] = '3';
//它的正确理解:
(char*)(name[2]) = '3'; //正: 把 name里面的第3个 char 强制转换为 char*
//这似乎是你的理解:
((char*)name)[2] = '3'; //误: 先强制去除 name 的const修饰,其后修改它的第3个字符
二、你的第二个错:做事不认真
有意思的是,你看了编译错误,并且将它翻译成中文(或者VC本来就能报中文),下面这话是你问题中的原文:
//编译器直接报错,const char[13] 不能转成(char*)
我试了一下使用GCC编译的情况,应该是一个警告和一个错误:
warning: cast to pointer from integer of different size
error : lvalue required as left operand of assignment
附加指出的错误位置是:
(char *)name[2] = 'M';
^
里面可有出现一个“const”不? “cast to pointer from integer ……”中的“pointer/指针”及“integer/整数”丝毫不能引发你的好奇心?
你的第一个错误,本有机会在此刻得到纠正,但你没有,你看似先入为主,其实就是没有认真过大脑地,继续往错误的人生道路前行,就差掉进犯罪的深渊。结合你的上下文,此时你应该是得出: “编译器可以在这 种 代 码 形 式 ”下正确识别及实现“const”的相关限制。
或许: VC真的报“const char[13]不能转换成(char *)”?
三、你的第三个错:甩锅太随意
然后,你开始测试另一种代码形式的测试。那个形式有模板、有强制转换,复杂度略高,并且结果与你事先认为的不同,于是你开始“屈(甩)服(锅):嗯,一定是C++太复杂,所以它出现这种奇怪的,前后不一致的行为也是正常的。于是判定,这应该要从更复杂层面(编译器实现)才能理解的了……
铺垫已足,强行插入:
很多小白看问题看到这里,也该差不多进一步强化了C++的印象:“这玩意太复杂,复杂到语言自己都能自己打架,也就一堆老人会去看它的底层编译原理实现才能明白这门语言的脾气的……还是早早放弃C++保我一头青丝吧”
其实,第二个案例中,全部“精华”就在这一句:
f((char*)name);
再精一点,就是:
(char *)name
既然是要做“对比”分析,那就再对比一次,字面上的对比:
| 甲组 | 乙组 | |
|---|---|---|
| 疑惑 | 奇怪,C++编译器会检查以下const | 奇怪,C++编译器不会检查以下const |
| 代码 | (char *)name[2] | (char *)name |
然后有“百思不得其解”:
“请问是什么原因能让C++保持在运行之后占有那块内存却无法写入的?”
这是一个好问题,但这不是初始问题应该衍生出来的好问题。因为如此轻轻松松跳过编译期的警告和错误,直接杀入运行期更深层次问题的思考——无助于原始问题理解,还会误导很多人,前面说的初学者,还有——可怜,辛苦一个个技术大牛恨不得从CPU的电路实现帮你说起……
以下是用来欢乐的:
女:“抱歉,我们真的不合适。”
男:“为什么!为什么你会怀疑结婚以后我们之间会在某些事情上不和谐?”
女:“我没有说结婚以后的事啊??”
男:“那你为什么要说我们不合适呢?!”
对应——
编译器:“喂,警告你哦,你这里要把一个整数转强制换成指针,它俩的尺寸都不一样呢。这样合适吗?”
程序员:“你丫的,你是怎么做到常量一会儿可改一会儿不可改的?!”。
编译器:“我没提到常量啊。”
程序员:“那你为什么要提‘cast to’!!!”
考虑到一些答案(可能是受你误导)基本答错了,下是正面回答。
首先,“在C语言中,强制转换基本是能成功的”——但这只是上半句,还有下半句非常重要: “如果一次强制转换不能成功,那就再来一次”。
按照这一原则,再做次对比:
甲组
(char *)name[2] ,就属于下半句:name[2] 是一个字符类型,char在C/C++归属于“整数 ”类系,即,它基本可以视为一个取值范围很小的 int ——就算不知道这些,直观上也应该很清楚:把一个 值 转换成一个地址(指针),编译器不会轻易放行的。于是报错。
编译器为什么在这里要报错?因为编译器认为你很有可能在这里是写错了。
又,编译器为什么会怀疑你在这里很有可能写错了?
因为制定语法的人认为,人类在这里很可能犯一种错:忘记各类操作符的优先级。比如这里name之前的“强制转换操作(type)”和后面的下标操作 [ ],到底哪个优先级或结合率高呢?
制定语法的人是不是太小看俺们C程序员的水平呢?
至少我在这个问题和这个问题之下,看到了好些个人犯了这个错。这无关你编程高低,只要是人,就容易犯这种错——这种低级错误;优秀的编译器,从他们的祖爷爷那一代开始,就知道的自身背负的一个重大责任:纠出人类写代码时容易犯的低级错误。
乙组
(char *)name;属于上半句,可以成功。为什么?因为你都已经这样写的,而且这样写就算让一块砖头来阅读,它也可以清楚的知道你的意图就是要强制去除name的const属性。编译器是程序,而你是人。程序可以帮人纠正低级错误,但不能阻止人类的意义明确的高(复)级(杂)行为啊。(回忆一下C++的原则:永远相信一个程序员可以做出多好的事的重要性,可比永远怀疑他会做出什么错误的事重要……)
意义明确,语法正确就不阻止这个程序员。因为,搞不好这个程序员就是想在程序运行时看看什么叫段错误,比如:他是一个教编程的老师,这位老师想给学生演示一下叫段错误。我不能拦着他。编译器,特别是C/C++编译器就是这么想的。结合当前例子,假设它看到程序员将甲组那行强制转换代码改成如下:
((char*)((long)(name[2])))[0] = '3';
有哪个程序员会因为犯“低级错误”而写出这样的代码?代码写成这样子,只能是故意的。
看的人更不会犯错,因为不管是谁看到这代码,都会一边骂骂咧咧,一边打开头脑里的那个CPU水冷系统,开始全力人肉分析这是在干嘛。
这时候,C++和C就开始体现语言个性上的不同了。C++觉得这样的代码太为难程序员了,完全可以在保持代码“丑”的同时,还保持直观。注意,这里又涉及C++的两个原则:一、当你干的事情很丑,那么就应该让对应的代码也很丑。二、就算丑,也应保持直观。功能相同,但是完美符合这两条原则的写法是:
reinterpret_cast<char *>(name[2])[0] = '3';
“reinterpret”是"重新解释",并且括号就一层,转换就一次,所以看这行代码时,程序员的大脑CPU基本上保持波澜不惊,一眼即可人肉解析出代码的意图,同时嘴角露出一丝不屑:好丑。