
视频
1. 作为人类工具,计算机的最大特点
上一节课,我们重点学习"冯诺伊曼结构",然后有一点小沮丧:生活中许多工具,居然都可以和以程序员的的祖师爷命名的 “冯诺伊曼结构” 扯上关系……
那我们学习计算机编程,和我们学习如何使用挖掘机,也没什么区分嘛?本来嘛,所有工作都是平等的……
以马桶为例我们做一个对比———
| 对比项 | 计算机 | 马桶 |
|---|---|---|
| I/O | 输入输出通道会拥堵 | 下水管道会堵塞 |
| 内存 | 某些程序会占用大块内存,导致系统变卡,很痛苦 | 有些人光拉不冲,导致数据漂浮起来,以致从内存直接溢出的地面,也很痛苦! |
| 算力 | 经常感到自己运算能力不够强大 | 经常感到自己“运算”力不够强劲,特别是碰上粘性强的数据 |
| 外存 | 程序运行一半地发现外部数据未准备好 | 程序运行一半,才发现位于外部的手纸未准备好 |
和马桶进行对比之后,计算机可能已经开始怀疑“机生”:史上最伟大的工具和那个"屎"上最伟大的工具如此相似,计算机尊严何在?!而程序员难免也会有一些困惑:坐在电脑前……跟坐在马桶上都只是在做"输入"操作吗?难道就没有一些本质上的区别吗?
上一节课说过:计算机既可以输入数据,也可以输入程序;或者说,程序也是一种输入数据。对应的,计算机可以输出普通数据,也可以输出“程序”这种数据。可以输入、输出“程序”,这就是计算机和普通工具的重大区别!计算机也因此拥有两个重要的功能特性:功能扩展性和功能可升级性。
- 功能可扩展性:即:通过输入新的程序就能计算机拥有新的功能;让计算机的功能越来越丰富;
- 功能可升级性:即:旧的程序输入,却能输出新的程序;让计算机的现有功能越来越强大;
这两个功能特性都是普通工具所不具备的。反过来说,如果普通工具具备了这两种功能特性,那通常正是因为:它内嵌了一台计算机。
基于以上特性,计算机拥有两种典型的用户:普通用户和程序员用户。普通用户使用已经存在的程序,而程序员用户则可以创造无穷无尽的新程序!仅从这个关系上讲,程序员用户在普通用户面前简直是“神”一般的存在!
随着计算机向各行各业的推广、渗透,越来越多的普通工具开始嵌入计算机。或许有一天,马桶也会区分出普通用户和具备编程能力的用户。
2. 指令、指令参数、指令集
2.1 相关定义
第二节我们说过:编程就是按照特定的逻辑,将一些简单的功能加以编排。那么对于计算机来说,功能简化、简化到最底层之后,就是在执行一条条指令。程序也正是由一条条指令所组成。那么我们就有了程序的第二个定义:程序就是指令和指令所需参数的各种组合;包括:指令和指令、指令和参数,以及参数和参数的组合。
想要更好的理解指令,同样可以借助生活中的工具。生活中每一种工具,都拥有自己的一整套指令。“一整套指令”,通常我们称为“指令集”。比如锤子、绳子、钳子等等,都拥有各自的一整套指令。指令可以拥有它自己的参数。以“敲”为例,根据它的力度大小进行量化之后,就可以得到不同的参数(比如敲击力度)。
回到计算机指令,计算机处理器的机器指令常见分类有:
- 内存操作:比如之前我们演示过的“内存取址”,或者将内存中两个字节的内容交换;
- 算术计算:典型的如:加、减、乘、除。
- 控制转移:程序由多条指令组成,那么程序在运行时,有可能按照顺序的:1→2→3→4 地一条条往下走;也有可能因为某些需要,跳过其中一两条,比如:1→3→5→7→9 地往下走;这就叫“控制转移”。
计算机的处理器有不同的厂商,有不同的型号,彼此的指令,可能互相兼容也有可能互不兼容。
2.2 实践:二进制指令长什么样子?
下面我们做一个上机实践,看看我们曾经写过的,用于以“Hello World” 的6行C++代码,对应的机器指令长什么样子。
这一次我们需要打开这个网址:Compiler Explorer (编译器专家) 。
在左边输入一段熟悉的 C++ 代码,共6行:
#include <iostream>
using namespace std;
int main()
{
cout << "Hello World" << endl;
}
如果你输入正确,在右边就能够看到它的编译结果(为方便排版删除过长内容,以 … 表示):
.LC0:
.string "Hello World"
main:
push rbp
mov rbp, rsp
mov esi, OFFSET FLAT:.LC0
mov edi, OFFSET FLAT:_ZSt4cout
call std::basic_ostream<char...>& std::operator<<(... char const*)
mov esi, OFFSET FLAT:_ZSr_tbasic_ostreamIT_T0_ES6_
mov rdi, rax
call std::basic_ostream<char...>::operator<< (...)
mov eax, 0
pop rbp
ret
大家首先可能注意到:最顶上躲了一个"Hello world." 这个字符串,这正是之前我们在课程中说过的:代码中直接使用的字符串,在编译之后会成为可执行程序的一部分。将来程序执行时,它也就随之被加载到内存。
结合本课的重点,请注意汇编中的 “push” 、 “mov(e)”、“call” 等英文单词或者字符。这些单词对应的就是:计算机的一条条指令。而每一条指令后面这些字符就是它在这一次执行时所需要的参数。二者结合起来:就得到一个程序。
那么计算机指令,是不是就是这一些英文单词呢?也不是。因为英文单词仍然是为了照顾人类的阅读习惯。实际上计算机看到的指令是一个个数字。
在新版的 https://gcc.godbolt.org/ 网站内,请点击如下位置:
即,勾选 Output 下的 “Compile to binary object”后,将看到二进制指令的程序:
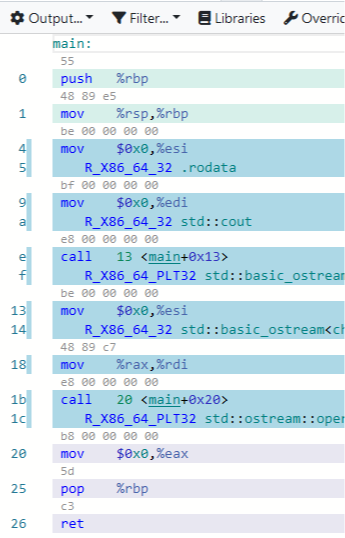
现在,每一条英文汇编指令下,都给出对应的,基于数字的指令,比如 “push %rdp”,变成了三个数字: 46, 89, e5。注意,数字真要采用二进制显示的话会非常长的长,所以实际用的是16进制。16进制数除包含0到9之外,还包含字母 a到f 用于代表10、11、12、13、14、15。关于各种进制的换算,可以选修《白话C++》的基础课程。
3. 高级语言和高级语言的取舍
使用数字表达的机器指令是专门为机器的处理器设计的,所以处理器在读取、加载以及运行这些指令的时候,非常的方便而且高效。但是,如果让人来阅读这些密密麻麻指令,就很容易犯晕。哪怕,我们将数字表达的指令,改成用前面所示的,用英文单词来表达,即:“汇编语言”,在使用方便性方面,也无法带来根本性的改善。因为,指令之所以难用的根本原因在于:它的功能颗粒度非常细。直接使用一条条指令来编写一个复杂的软件,比如 Photoshop,那就有如直接使用一粒粒沙子来盖一座高楼。
事实上,就算是用来写一个简单的 "hello world"的功能,刚才我们也看到了:6行的C++代码对应的密密麻麻的汇编指令,一个屏幕都放不下。
为了更加高效的编写程序,人们很快在机器语言或者汇编语言的基础上,发明了很多的高级语言。之所以称作高级语言,是因为这些语言在设计上,不再完全的贴近、贴合机器的实现结构的需要;而是开始考虑人类的思维模式的需要。这些语言所写出来的内容,我们通常称之为“代码”。
机器并没办法直接读懂代码,更没办法直接运行它们。所以通常还需要一个程序将高级语言写的代码“翻译”成机器语言,这个翻译过程的专业的叫法是:“编译”。
机器的实现结构是一种客观的存在,可是什么是人类的思维模式?答:没有标准答案。
在编程语言的发展史上、出现了成千上万种高级语言;它们都试图在机器的实现结构和人类的思维模式之间取得某一种平衡。
每一门语言都会有自己的设计倾向,没有十全十美适用一切情况的编程语言。每一门语言它都会在设计上,做出自己的取舍。关键在于:好的取舍是什么?
答:好的取舍,必然是:目标一致的、脉络和思路一致的、“三观”稳定的取舍。而差的取舍是:东一榔头、西一棒子,见一个语言特性,爱一个语言特性,很容易出现始乱终弃的取舍。
语言的取舍,很像我们的衣着打扮。你要保持风格一致,你要服务于特定的穿着目标。比如你这一次的目的是商业演讲;那么,西装、皮鞋、领带、衬衣,这是好的取舍。如果不考虑目的,随便来:穿个西装、套个睡裤、人字拖、配上网眼袜……
这样的打扮,就是乱七八糟的取舍。
学习一门编程语言,不能只学一个表面语法,一定要在学习的过程中,多留心、观察、思考这门语言的“三观”是什么。切记和你所要学习及使用的编程语言,保持三观契合!顺着它的小性子,不要和它逆着干。
有些同学跟我说:“老师我不是这种人,我怎么可能这样?到什么山头,唱什么山歌?这种摇摆的态度呢?!”
这样意见可不对!我们不是在谈什么精神文化层次的东西,我们是在学习一个客观的技术。而,学习技术一定要做到知其然,还要知其所以然;才有可能达到事半功倍的效果。
4.C++原则:诸事诸物,当有出处
C++语言的三观是什么,今天没法说太多,只说关键的一点:C++,它会做程序员的“管家”,但不做程序员的“精神导师”。
意思是:一些琐碎的小事,它(C++语言)会帮你盯的紧紧的,但是那些要害的大事,那些高级的事情,那么程序员你是自由的,你想怎么样就怎么样。
举个例子:出门办事穿什么风格的衣服,它不管;但是,你的裤子拉链没有拉好,这个事情,C++它管。
再举一个更贴近的例子:比如,你认识了一个新的女朋友并且要带她出门,那么这件事情会被C++“盯上”,因为它还不认识这个女生;所以你一定要告诉它:
- 这个女生是从哪里来的?
- 她是什么类型的女生?
至少要交代清楚这两点,才能带出门。否则C++可能会认为:这事情不安全。这个例子谈到了C++编程的一个重要原则——“诸事诸物,当有出处”。
再来看一个例子:这次是老公和老婆之间的一小段对话,请大家认真“听”,并及时注意到:这当中有什么东西没有出处?
“老婆,我爱你”
“嗯”
这个没有问题,老公对老婆的爱,通常是有出处的,不然怎么成为夫妻呢。继续:
“你喜欢这个包吗?”
“嗯”
LV包也没有问题,因为就在手上提着呢,有出处!继续 :
“老婆我想静静”
???
哎~~ 这一下,经典问题来了:“静静”是谁?“静静”没有说到它的出处!
看代码:
cout << "Hello world" << endl;
这行代码需要的 “cout” 和 “endl”,和"静静"一样都是一个符号,既然是一个符号,它代表什么?来自哪里?就必须有交代、有出处。
在实际代码中,这两个符号的说明,来自于这行代码:
#include <iostream>
这行代码中,iostream 是一个文件。而“include” 是包含的意思,包含这个文件,就相当于在当前代码中打开这个文件,并在文件内容中查找到了"cout" 和 “endl” 的说明。如此,这两个符号就有了出处。
实际情况是不是这样子呢?我们马上可以做一个测试。将上面说的那行代码,注释(或者直接删除)掉:
// #include <iostream>
这次再编译,就能看到编译报错。报错内容简化后是:
error: 'cout' was not declared in this scope
error: 'endl' was not declared in this scope
翻译为:
出错:'cout' 在当前范围内没有声明
出错:'endl' 在当前范围内没有声明
归纳一下,cout 和 endl 两个符号的出处的说明,是在 iostream 这个文件中,由于包含(include)该的文件的代码,被我们注释掉,于是编译器开始抱怨:“ xxx 在当前范围内找不到声明啊……”。翻译成老婆说的话,就是 “ ‘静静’ 在我的记忆范围内,你可是从来没有报备啊?”
还没完,继续前面的例子,针对老婆的问题,老公回答如下:
亲爱的,别急,你等等……
等什么呢?
老公在代码中添加了一行:
#include <老公朋友圈>
哦?!原来“静静”还真的是老公的朋友啊!
根据前面所说的方法,老公现在明确的包含了 “我的朋友圈” 这个文件,关键是,在这个文件中,还真有 “静静”的声明:一个漂亮的女性朋友。
现实中的老婆会不会因此更加生气,我不知道。但是,你现在是知道C++的“三观”的。所以,C++编译器,现在是它对程序员,那是一个放心!
继续,继续……
为了避免类似的错误,这次老公又主动加了一个包含:
#include <老公的同事圈>
没想到,这又带来了另外一个问题!朋友中有个静静,万一同事中也有可能有个静静……嗯,一贯抓小放大的编译器老婆(C++),这回可能会有新的担心:是朋友静静还是同事静静?“静静”的出处又要打上一个问号了。
C++是一门在细节上很严谨的语言,所以实际情况是,不管有没有真正存在重名,这样的问题都必须加以预防。
预防方法之一是加上这行代码:
using namespace std;
即:使用名字空间 std。这行代码的具体作用是什么?让我们在实践中学习,我们先恢复第三行,然后把第5行注释掉(或直接删除):
#include <iostream>
// using namespace std; 这行被注释
int main()
{
cout << "Hello World" << endl;
}
再编译,又将失败。出现的错误,竟然还是 “找不到 cout 和 endl” ?为什么?不是已经有 include <iostream> 吗?
原来,这两个符号在这个 iostream 里头的声明,它的名字是有全称的。更准确地说,名字需要带上特定的前缀 (注意,这仍然不是最准确的说法,但先按 “前缀”理解)。
cout和endl的前缀是 std,前缀和名字之间,使用 四个点(两个英文冒号)即:
std::cout << ... std::endl;
这个前缀的作用是什么?这里的前缀就是名字空间。表达一个名字所起作用的范围。比如,007 的大名,可能就只在(曾经的大)英帝国起作用……
“你也不打听听,我叫邦德!我可是 007”
“这里是中国,又不是英国,我管你 007 还是 008,一概不认识!”
“std” 是 “standard / 标准” 的简写,它是 C++ 标准库的名字空间;所以 std::cout 就是指 “来自 C++ 标准库里的那个 cout ”。下面我们用 “全称” 方式,来使用 cout 和 endl:
#include <iostream>
int main()
{
std::cout << "Hello World" << std::endl;
}
请注意,第二行现在是空的。
再编译、执行一下,一切又恢复正确。
虽然这么写很严谨,但是每次写这个前缀(示例代码中需要写两次)有时候会觉得,比较啰嗦,怎么办呢?通常我们的建议是:不要怕啰嗦,并且在越大的代码中,越是要不怕啰嗦,坚持写完整的全称。在本例中这样的,只一个源代码的小程序里,既不想啰嗦,又想保持一定的严谨性,就是,恢复 “using namespace std”,于是就可以不再处处写 std:: 了,而这正是,我们一开始示例的那个版本:
#include <iostream>
using namespace std;
int main()
{
cout << "Hello World" << endl; // 没写名字空间限定
}
"using namespace std;"的作用是:告诉编译器,如果当前源文件中,后面代码中如果遇上不认识的,没有出处的符号,就尝试先当作是 std:: 范围内的符号处理……
这并不是一节讲 “namespace” 的C++课,我们只是用它来作例子,说明 C++ 是如何在细节上管着我们的:一个符号,不仅要有它的出处、类型的声明,而且每次用到它,最好明确地说出它所属的范围。
试想:家里养了一只宠物猫,平日里大家都叫它 “性感的小猫”……
老公:“今晚我想带 ‘性感的小猫’ 出门……”
老婆:“你特么地说清楚是哪里的‘性感的小猫’!!!!”