
0. 视频
1. 生命周期

只要是数据,就需要占用内存空间。程序将内存分成多个区,其中最重要的是栈区和堆区。放在栈区的数据,称为栈数据或栈对象;放在堆区的数据,称为堆数据或堆对象。二者最大的不同,在于数据的生命周期不同。
1.1 栈数据的生命周期
在栈区内存中的数据,它们什么时候死,是由所在代码结构决定的。最典型的,C/C++中,函数、流程结构(比如之前学习的 if/esle、while)等,所拥有的一对花括号,即形成一个语句块(也称代码块)。栈数据会在所在的最内层代码块结束出“死亡”;且遵循同一层级的栈数据,“先定义的后死,后定义的先死” 的原则。
- 例1:
int main()
{
Object o;
return 0;
}
本例,o的生命周期始于定义,终于 main () 函数体的 } 之前 (即,在return 0 之后)。
- 例2:
int main()
{
Object o1;
Object o2;
}
01和02都将在函数体结束处死亡,但o1先定义故后死,o2后定义故先死。
- 例3:
int main()
{
{
Object o1;
}
Object o2;
}
本例,o1 拥有独立的代码块,代码块处于 o2定义之前,因此 o1 将先生也先死。
- 栈对象生命周期测试代码:
#include <iostream>
using namespace std;
struct Object1
{
Object1() { cout << "哥生" << endl; }
~Object1() { cout << "哥死" << endl; }
};
struct Object2
{
Object2() { cout << "弟生" << endl; }
~Object2() { cout << "弟死" << endl; }
};
void test1()
{
Object1 o1;
Object2 o2;
}
void test2()
{
{ Object1 o1; }
Object2 o2;
}
int main()
{
test1();
cout << "~~~~~\n";
test2();
}
1.2 堆数据的生命周期
1.2.1 创建堆数据的语法
类型名 * 对象名 = new 类型名();
当不初始化初值,或类型(结构)的构造函数不需要入参时,() 可省略。
另外,很多情况下,上面的两处类型名完全相同,此时可使用 C++11 标准,将第一个类型名用 auto 代替,如:
auto* o = new Object();
或
auto* o = new Object;
内置类型数据,也可在堆中创建,并且可以 在上述语法中的 () 填写初始值 ,比如:
int* i = new int(12); // 创建 名为 i 的 int 类型堆变量,且初始值为 12
更多例子如:
int* i = new int;
int* age = new int(12); // 带入参构造
char* c = new char(‘A’);
double* money = new double;
bool* sheLoveMe = new bool(false);
auto* year = new int (2024);
1.2.2 杀死堆数据的语法
一个堆数据创建出来,且分配了堆内存后,如果不释放,它将一直存活(直到程序退出)。“杀死”常规堆数据的语法是:
delete 对象名;
如(结构类型数据):
auto* o = new Object;
// 使用 o
delete o;
或(内置类型数据):
int i = new i(12);
cout << *i << endl; // 将输出 12 , *i 解释见后
delete i; // 杀死!
1.2.3 堆数据的生命周期
从 new 创建并获得堆内存开始,到被代码主动 delete 之间,堆数据都是“活”的(即一直在占用堆区的内存);下面的例子中,函数 foo()每被调用一次,都将在堆内存中占用一字节内存,并且在每一次调用结束后都未释放该内存,从而造成 “内存泄漏” 。
void foo()
{
bool* b = new bool (false);
std::cout << b << std::endl;
}
int main()
{
foo();
}
2. 内存模型

2.1 栈对象内存模型

代码:
void foo()
{
int age = 12;
}
foo() 被调用时,将创建一个类型为 int 的栈数据,该数据初始值为 12。此值存放在栈区;在特定系统下, int 占用 4个字节的内存。
一个字节的内存,类似于一间不可再分的房间;每一字节的内存都拥有一个地址,类似于房间的门牌号。图中 12 所存放的四个字节的内存地址为 8001~8004 。
实际内存地址数值通常比较大,此处为形像易理解,故意简化为类似门牌号码;另外,内存的存入次序,也不一定是如图中的从小到大排列。
通常称第一个字节的地址,为数据的存储地址,即图中 12 的存储地址为 8001。
2.2 堆对象内存模型
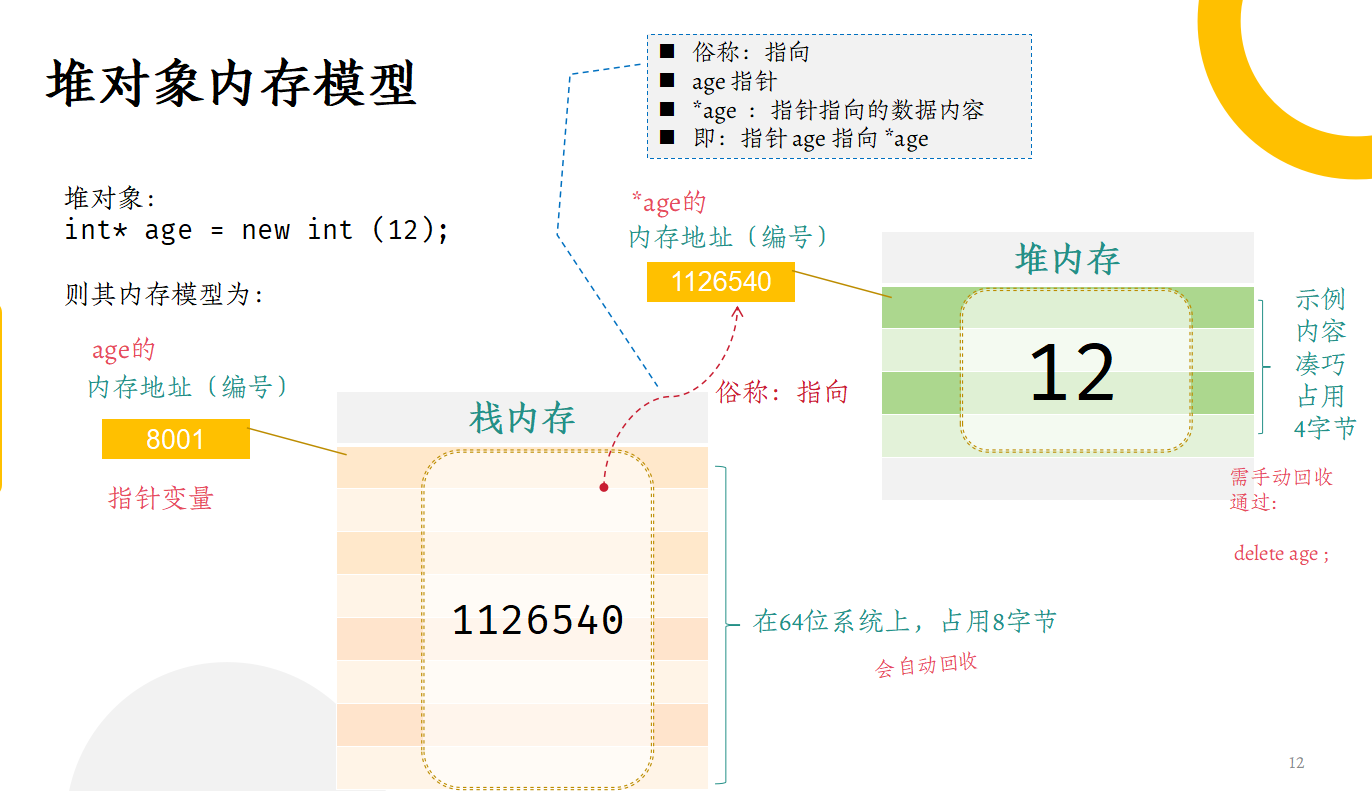
代码:
void foo()
{
int* age = new int(12);
}
执行时,将首先在栈内存中占用固定大小的内存(64位系统下固定为8字节,32位系统下固定为4字节);同时在堆中申请并获得(至少)可存放一个 int 的堆内存(特定系统下为 4 字节),并将初始值 12 存放于其中,再将其地址存放于栈中分配的内存里,本例为 1126540。
此过程,至少涉及两个内存地址,一个在栈内存,即图中的 8001,一个在堆内存,即图中的 1126540。
当一块内存中存放的是另一块内存的地址,我们就称前一块内存指向后一块内存。在本例中,即地址为 8001 的栈内存,指向地址为 1126540 的堆内存。
此时,也可将两个地址视为两个数据,则称前一数据为指针数据或指针变量,即,示例中的 age 是一个指针变量,它指向的内容,则使用 “*age” 表示。
由于 age (即指针变量) 存储在栈中,因此也遵循栈区数据的规矩:会依据所在代码块的结束而自动回收。即:图示中的地址为 8001 的八字节栈内存,会在 foo() 函数的结束时,自动退还,而因为没有 delete ,未能归还的内存,是存放 12 的,四个字节的堆内存。
想要释放指针变量所指向的内存,如前所述,语法 delete 指针变量。示例如下:
void foo()
{
int* age = new int(12);
delete age; // 正确写法
delete *age; // 错误写法
}
3. 可见区域

通过四个例子代码加以了解数据的可见区域。
- 例1:
int test1()
{
int i;
int i; // 错误
}
说明:同一生命周期内,存在完全同名的两个数据,非法。
- 例2:
int test2()
{
int i;
{
i = 999; // 外部的i
int i;
i = 888; // 内部的i
}
}
说明:嵌套(包括多级嵌套)的内部代码块,可以看见及访问外部代码块之前定义的数据(例中:i = 999),除非内部代码块出现同名数据,此时看见的内部的同名数据(例中:i = 888)。
- 例3:
int test3()
{
{
int i;
}
i = 999; // 错误
}
说明:外部的代码块,看不到哪位位于其前定义的内部代码块中定义的数据。
- 例4:
int test4()
{
{
auto* i = new int;
}
delete i; // 错误
}
说明:外部的代码块,看不到哪位位于其前定义的内部代码块中定义的数据,哪怕其前定义的内部代码块中定义的数据仍然活着……