
一、新需求
上一节课《从零开始,实现日志流》 (含付费内容)中,我们通过 90 行的代码,实现了一个简单的日志系统,不过,它具备两点还算专业的功能:
- 支持使用 C++ “风味十足”的“流/stream”的方式,输出日志;
- 支持向屏幕输出日志内容的同时,可选地向指定磁盘文件输出相同的日志内容。
光这两点,显然不好意思向同事们推荐推荐这套日志系统,甚至作为学习项目,放到 github 上,都不太好意思向各家公司的C++面试官们展现你的成果……
怎么办?简单!只要加上下面这些需求的实现,那么,你的项目,将一下子变得非常有专业性、实用性以及新颖性三大光环(此处需结合你的学生或C++新人身份)。
- 实用:全可以在中小项目上使用;
- 新颖:和某些流行的C++日志系统相比,也有自己的特色功能和方便性。
而作为一个学习项目,通过本课实战,我们将学习到以下C++编程的重要知识点:
- 多线程编程中的资源访问并发控制(包括互斥量的两种经典加解锁方式的实践);
- 借助 “Proxy” 设计模式,实现对默认行为的额外控制,包括可选的并发控制和可选的“空行为”;
- 友元关系的应用。
涉及到其它知识点主要有:
- 临时对象作为函数返回值时,move 行为的自动启用(C++17);
- 来自 c++11 的 chrono (时间库)的应用(C++11);
- 如何通过前置声明,解决类型之间的交叉引用;
- 理解(跨语言的)日志级别约定;
- 多级名字空间的新写法(C++17)。
来看看新增哪些需求点。
需求0-要有专门的 namepace
这不算什么功能,不过是我们将自己写的代码库用到别的项目之前的基本 “礼仪”。
在我们的例子中,名字空间就叫 d2school::log 吧。即第2学堂提供的日志系统。
需求1-支持日志级别、时间自动输出
这也不算什么有特色的功能,不过是所有日志系统的基本功能。但是,其中的等级名称,我们的日志系统可以简单选择使用中文或英文名。
——这听起似乎更不专业了!很不国际化啊……然而,对于一个中国的程序员来说,“想要一个使用中文显示的日志”,很过份吗?在实际的不少项目中,大有用武之处!
带级别和时间的日志真实运行效果如图:
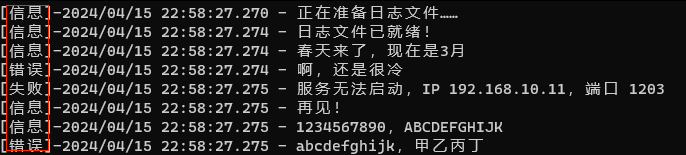
其中标红部分即为日志级别,当前使用中文名称。另外你应该也注意到了,时间精确到毫秒。
需求2-支持原始内容输出
没错,相当多日志系统在提供了前一点的功能之后,就从此丧失了 “简单地输出一行内容” 的功能了……比如,有时候,我们就是想简单地输出一条分隔线……可是它也带上了日志级别和时间……这会让许多人人,特别是处女座的程序员们,很不爽。
这个问题,我们解决了……
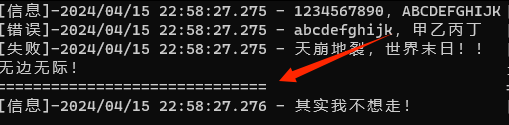
图中那条由等号组成的分隔线,以及其上的 “无边无际”,就是以 “裸奔” 形式输出的日志……嗯,不忘初心很重要!
需求3-支持日志输出的级别控制
这也是一个日志系统必须的功能。日志级别通常有大小之分。常见的级别从低到高有:
- 无 NONE / OFF :用于关闭整个日志输出,实质不是一种级别
- 跟踪 / TRACE
- 调试 / DEBUG
- 信息 / INFO
- 警告 / WARN
- 错误 / ERROR
- 失败 / FAIL
有实质意义的各级别,详细解释如下:
- 【跟踪】:用于输出系统运行的完整步骤,或称对系统的运行进行“原理性”的、“解剖式”的的展现;这类信息需要由程序员事先写好。尽管TRACE日志对于排查任何问题,都有帮助,但由于它会造成事无具细的,大量的日志输出,所以,如果不遇到大问题,我们通常不会打开这个级别。另外,除非很重要且很复杂的系统,否则通常程序员们也不太喜欢事先写好这些信息。
- 【调试】:通常是用于解决某个特定故障,而特定加上的调试信息;通常在特定问题确定解决之后,就会从代码中删除这些信息(作为对比:TRACE 信息通常会保留)。
- 【信息】:有利于对系统的运行进行日常观测和日志分析(包括统计)的信息输出。通常也是一个系统日常运行时的默认日志级别。
- 【警告】:系统出现某些不正常表现,但并不会造成系统自身运行出错,也不会造成业务逻辑出错。典型运行环境问题:预见磁盘空间可能不足,发现网络严重卡顿;或者用户操作异常:用户反复尝试登录,用户超高频访问同一资源等等……
- 【错误】:系统自身运行出现故障,或业务逻辑存在错误,但不影响系统继续对所有人提供其它服务,或对出问题之外的用户提供当前服务。
- 【失败】:系统自身运行出现严重故障,或出务逻辑存在严重错误,造成系统已无法向所有人提供某类特定服务,或者无法向某些人提供任何服务,甚至已无法向所有人提供任何服务。典型如:数据库访问失败。
以上仅是错误等级的一种划分和描述方法;比如,有些日志系统会有更多的等级,比如在【错误】和【失败】之间增加一级【高危】(CRITICAL);另外,具体错误如何归类,也存在很多不同实践。
运行时,可以修改日志系统要输出的最小级别。比如设置最小输出级别为【警告】,则等级较低的【信息】、【调试】、【跟踪】等日志内容,将不被输出。
需求4-支持可选且高效的并发安全控制
如果你的程序存在并发,并且需要在多个线程下使用同一个日志对象,那么,没得选,你必须打开日志系统的并发安全控制,否则日志内容将是混乱的。
如果你的程序根本不存在并发(这并不少见),或者不同线程使用各自的日志对象(这比较少见,但特别适合某些特定类型的系统),那么,你可以关闭日志系统的并发安全控制,从而获得更好的日志输出性能。
等等,那么,是不是在有并发的情况下,我们就允许日志系统的性能变得很差呢?
当然不允许!因此我们又有一个附加要求:哪怕在并发时,对 logger 对象的加锁操作,也要最小化:仅在我们真的需要将日志输出到屏幕(std::cout),或者文件流时,才开始加锁。
由于 std::cout 必然是唯一的,而日志文件也是唯一的,因此对二者的加锁无可避免——因此,我们确实做到将加锁范围压缩到了最小。假设有两个线程:
// 线程1正在调用:
logger << "ABC" << "EFG" << Endl;
// 线程2正在调用:
logger << "123" << "456" << Endl;
虽然 logger 是同一个对象,但是,通过它记录 “ABCEFG” 和 记录 “123456” 将可以真实并行处理,直到二者都要输出 Endl 时,加进行加锁。
不过,后面课文中我们将看到:我们并不再直接以 logger 对象输出日志,而是通过 logger.Info() 、logger.Error() 的方式输出。
需求5- 代码控制在 300 行上下
这算需求吗?当然算,别忘了,这是一个学习案例。假设用30000行实现一个日志系统,也许功能非常强大,但完全算不满足是一个学习案例的需要。
不要3万行,也不要3千行,我们只要3百行,可以做到吗?
当然可以!包括日志类的实现,包括使用示例,以及包括注释,我们控制在300行上下。
300 行C++ 代码以实现一个完整功能,通常能让一个初学C++两个月左右的同学的学习性价比处于巅峰状态——不会因为太简单而所得草草,也不会因为太复杂造成学得不够扎实。
上一节课我们最后得到的代码,连带测试代码,大概是90行,这次的专业版本,连带,代码将膨胀数倍,因此,对新人来说,挑战还是有的,不会让你太舒服。
二、基本设计:引出代理对象
上一节课,我们已经可以通过一个log对象,实现如下“流”式日志内容输出:
logger << "服务IP:" << ip << ",端口:" << port << Endl;
它将得到类似如下的一行完整日志:
服务IP:127.0.0.1,端口:2323
2.1 输出日志头
在本课,因为需要区分这一行日志是什么等级,以【信息】,即 Info等级为例,现在我们希望代码变成如下形式:
logger.Info() << "服务IP:" << ip << ",端口:" << port << Endl;
即:不是直接通过 logger 对象输出,而是通过 logger对象名为Info()的方法的返回对象来这输出,这个返回对象是什么,我们一会再重点解释,现在先暂时称之为 “代理对象”。
此时的输出将自动加上等级和时间信息:
[INFO]-2024/04/16 15:10:57.328 - 服务IP:127.0.0.1,端口:2323
相应的,如果是要输出一行调试(Debug)级别的日志,代码应该类似:
logger.Debug() << "当前用户会话是:" << user.session_id << Endl;
得到的输出是:
[DEBUG]-2024/04/16 15:22:07.180 - 当前用户会话是:sid3920335350
但是,前文在提及新颖性时曾说到,我们的日志系统不忘初心,仍然支持仅仅输出原始数据。因此,logger对象还有一个方法,叫Raw(),用法如下:
logger.Raw() << "======我是可可爱爱的分割线=======" << Endl;
将得到一行原汁原味的日志内容:
======我是可可爱爱的分割线=======
这就是logger在调用 Info()、Debug(),或 Raw()时,需要额外做的事之一:判断,并在需要时,负责输出头部内容(等级、时间)。
基本上都需要输出头部内容(等级、时间),除了 Raw() 的情况。
2.2 控制最小输出级别
Info()、Debug()、Error() 等函数,名字就说明了当前日志的级别,然后,我们就可以做一个对比:如果该级别比 “允许输出的最小级别” 还要小,就不输出。
Raw() 在此处又是一个特例,它只负责原汁原味输出内容,不受级别控制。
需要注意的是,这里有一个难点——
在输出一行完整的日志时,Info()、Debug()、Error() 等函数只调用一次,比如:
logger.Info() << "服务IP:" << ip << ",端口:" << port << Endl;
例中,“ << ” 出现了 5 次,每次都输出一小截内容,这五次输入都需要拿当前日志等级(即 INFO 级别)和 前面说的 “允许输出的最小级别” 作对比;可是,我们只在 Info() 函数调用时,知道当前日志级别是 “信息 / INFO”,等到真要输出日志内容,比如 “服务IP:” 时,我们要怎么知道它的级别是 INFO 呢?
一种方法是在调用 logger.Info() 时,修改 logger 对象的某个成员数据——但这样做很不合理!因为 logger 有可能在并发使用,假设线程 1 正在输出一行 “信息”,而同时线程 2 在输出一行 “警告” 级别:
// 线程 1 正在:
logger.Info() << "我是线程" << 1 << ",当前日志是【信息】级别" << Endl;
// 同时,线程2:
logger.Warn() << "我是线程" << 2 << ",当前日志是【警告】级别" << Endl;
- 并发冲突分析:线程1在执行完 “logger.Info()”后,会将 logger 对象的当前日志级别设置为“INFO”……
- 说时迟那时快,就在线程1要执行后面的输出之前,线程2调用了 “logger.Warn()”,于是将同一日志对象(logger)的当前日志级别修改成 “WARN” 级别了……
显然,并发会造成 “当前日志级别” 冲突,怎么办?
方法一:在 Info()、Warn()……等函数中进行并发加锁——但这会违背前面 “并发最小加锁”的附加要求:并发时,同一logger对象每次只能有一个线程在输出。以上面两行代码为例,假设线程 1 抢到了锁,那么,它将从 logger.Info() 开始,一直锁到最后的 “<< Endl” 操作……
方法二:在代码尾部的 “<< Endl” 时才开始加锁,而不是上来就锁。也就是说,无论前面输出多内容,在遇到 Endl 之前,统统是无锁,无销可以更好地保证日志拼装过程的效能。
方法二正是我们的要实现的。这种办法非常经典,经典到**GOF的《设计模式》**中肯定有它,经典到所有程序设计老鸟一见就要会心一笑:通过临时的代理对象来处理。更具体一点:让 Info()、Warn()、Error()……等函数创建、返回一个临时对象,由它来负责后续的输出,直到遇到 “<< Endl”,才交还 logger 对象处理。代理对象不需要加锁,logger 对象才需要。
为什么临时对象输出日志不需要加锁,logger 对象才需要呢?
真相简单到可能要令你“生气”:因为多个线程共享一个 logger 对象,多对一操作,容易冲突。而代理对象是在每次输出时临时创建的,“各玩各的”,不存在共享,当然就没有并发冲突问题呀!
是时候装X一下了:优雅的设计,从来就是简单的……
三、代理对象
前面说了,Info() 等方法,会返回一个代理对象,如:
……
付费内容
完整课文还包含后续的:
- 近 6000字 长文
- 4 段 合计 1 小时的视频
- 完整代码(含三个代码文件)
- 强化练习一份(作业,交卷后或获得本文作者批改)